Predicting publication year and generational language shift
Before end-of-semester madness, I was looking at how shifts in vocabulary usage occur. In many cases, I found, vocabulary change doesn’t happen evenly across across all authors. Instead, it can happen generationally; older people tend to use words at the rate that was common in their youth, and younger people anticipate future word patterns. An eighty-year-old in 1880 uses a world like “outside” more like a 40-year-old in 1840 than he does like a 40-year-old in 1880. The original post has a more detailed explanation.
Will had some some good questions in the comments about how different words fit these patterns. Looking at different types of words should help find some more ways that this sort of investigation is interesting, and show how different sorts of language vary. But to look at other sorts of words, I should be a little clearer about the kind of words I chose the first time through. If I can describe the usage pattern for a “word like ‘ outside ’,” just what kind of words are like ‘ outside ’? Can we generalize the trend that they demonstrate?
Most of the words I chose last time came out of the results of a principal components analysis I did earlier to see how vocabulary usage changed over time. That result gave me back a particular kind of word—those that change slowly but steadily over time. The Google ngram for ‘ outside ’ shows a steady rise: it also finds several words with a steady decline. (Reminder: I’m not using the ngrams data for my own analysis, but it serves as a nice check to use a different set to confirm trends I find where that dataset is usable).
That’s to say: these are distinctive words I use. They represent a very particular sort of change in language; it happens slowly, creepingly, and probably without much notice by historical actors. It even happens, I think, without much notice by historians: we tend to care about words that are contentious, that represent major changes, and as a result they tend to have spikes and plateaus. Some historical keywords do have some nice overall trend; but plenty of others tremble up, down, and steady.
Our standard ways of writing about causation in the historical profession deal worst, in some ways, with decades-long steady change: there will not be any single useful archival source to write about the long creep upwards of a word like outside, while there may be single people or institutions that themselves propel “Joseph Smith” or “Pragmatism” into common usage. (I think English and Comp Lit may actually have a better vocabulary for describing these long shifts not necessarily tied to individual people; Ted Underwood is doing some neat stuff looking at century-long patterns in language use on his blog, for example.) In some ways, that’s just what’s exciting about using computers to help read books: these are shifts in language over the longue durée, and they open up new prospects for being quite precise (perhaps misleadingly so) in describing changes that previously might have been murky or unknown. More on that later, hopefully. Also, I should deal more concretely with many of the other words we care about.
But first, let me take advantage of steady directional drift in language to think about how it helps us in identifying when books were written. I was talking to Jamie recently about dating anonymous Latin hagiographies from the 6th-8th centuries based on their word usage. This is something that we might be able to do fairly well with computers. (I’m sure there’s a bit of research out there that I haven’t read, actually). I could probably make some headway with the open library database. A full non-linear regression on publication year using all 200,000 words I have would be a major project, and I don’t see an immediate payoff for it. But one of the nice things about the pca analysis I did is that it breaks 10,000 words down to five or six dimensions that I know correlate to publication year. The data is already selected to be linear, so normal linear regression should work too.
That means I can build up a simple linear model that, given the vocabulary usage of a book, makes a guess as to when it was published. To help it out, since I know some genres lag behind the times and others ahead (second chart in linked page), I give it catalog number information as a variable to work with as well. The result accurately places somewhat more than half the books within a decade of their actual publication date. (R-squared = .56). I could certainly build a better model, but don’t need one right now: this is a good enough for the particular sort of slow, steady change that I’ve been looking at, and all the error should be smoothed out in the end anyway.
I’ll forgo too much exploration of that model, since it’s not my main focus here. (It does include some neat features, like the ability to find the most futuristic books in any given genre). But let me make a couple quick, eminently skippable notes with scatter plots to explore the error here. First, the overall error. Remember, I’m using publication year, which includes reprints, because I don’t trust the metadata very much on first publication year. The model almost never mispredicts by more than 50 years.
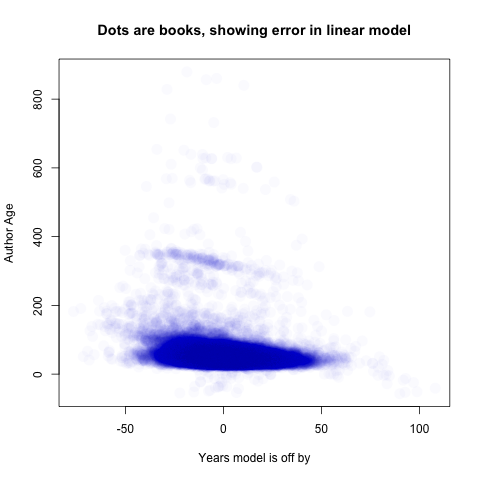
Basically all this chart below shows is that most books are written by people under 100 years old, but I have a few very old authors. The streak around 350 years old is Shakespeare, whose books are consistently predicted as published in the 1880s or so. That’s somewhat interesting—it means that a sample based on vocabulary from 1830 to 1922 is terrible at extrapolating out much past those boundaries.
Let’s zoom in to the section of the plot with realistically aged authors and fewer than fifty years of worth of error.
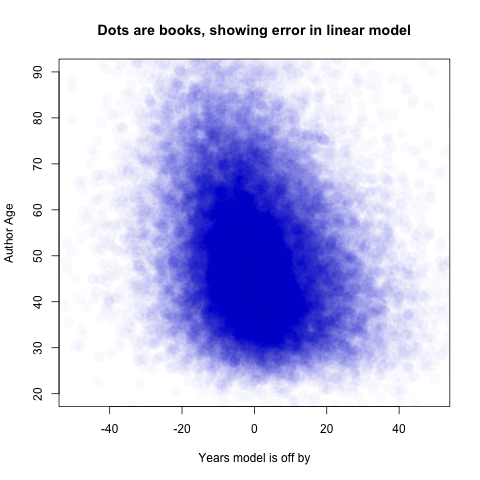
We can see that most of the error is not due to author age. It takes a computer to really notice the slight downward slant in the scatter (R = –0.21). That’s telling us that author age doesn’t explain the bulk of missing data, but that it might help some. A better model might explain some of the other variation.
This model, though, is good enough to explore the variations in some of my data. Last post, I looked at how percentage usage of words changed over time: now I can look at how predicted year changes over time:

For each combination of year and author age, the colors show what year my model thinks the books in that position were written. Let’s take books written in 1880 as example. On average, it thinks books by 30 year-olds written in 1880 were written around 1897; books by 50 year-olds look to it like they were written in 1891; and books by 70-year olds look like they were written in 1875. To go back to the language of my last post, an Angstrom theory of language would have 0 years of change for 40 years of age difference, and a Bascombe theory would have 40 years of change; this basically splits the difference with 22 years of predicted difference in the language of different aged authors. You can see that more generally in the slope of the lines towards the northeast; they aren’t horizontal (Angstrom) but neither do they match up with the diagonal aging lines (Bascombe).
So that means that of language change, half is because of generational displacement, and half because of individuals learning new words as the get older. (The extra two years towards Bascombe (22 instead of 20), let’s just pretend, are because of the relatively few republished books in the sample). That sounds about right to me. I felt like I might have somewhat oversold the aging component in my previous post, because I think it’s more important to notice that it’s there. To say it’s about half of all steady change in language (which, I should note, is not all change in language) means that it’s pretty important.
That, I think, more firmly establishes how important generational displacement is in driving linguistic change. I think there are still some productive questions to be asked about these charts, though, that get beyond that basic point. Here are some, from most to least technical.
How can we describe whether a word is type-Angstrom or type-Bascombe without having to eyeball these heat maps? With the results from the linear model, it’s easy to just look at slope. But most of the heat maps are a lot more splotchy–they don’t simply run in a straight line. I think I could kludge together an approach that works off of the slope of contour lines; that might be good enough.
The Bascombe-Angstrom model I described only includes countour lines running in two of the four cardinal directions. I’m pretty confident that most words should fall roughly between those two models, but there are other possibilities nonetheless. I talked a little last time about words that remain constant in usage across time, but vary in usage by different age groups; Willy asked in the comments about the fourth kind, where changes begin among older people and then filter down into the younger generations. I suspect there are very few words like that (although ‘ evolution ’, actually, is close). Am I right? What are those words, if they do exist?
What other aggregations tell us things about whether generations or intrasubjective shifts drive linguistic changes? I’d like to bring some of my genre data into this mess, perhaps, to see if young people drive shifts towards new disciplines or if it generally requires oldsters to lead the way. Or keeping it at the linguistic level, I wonder how shifts in the prevalence of topic-model generated topics over time correspond to changing ages.
To what degree are generalizable claims I can make about the role of generational displacement in linguistic change universal patterns, and to what degree are they an artifact of the particular historical period I’m looking at? I’ve been mulling over this New Yorker cartoon. Let’s say it’s right, and at one point there was no linguistic change. Once it started, did generational displacement immediately start driving half of it? Or was it across all generations at first? This would take a lot of data I don’t have (and that might not exist in sufficient numbers before the 18th century or so, and that’s locked inside copyright for the post-1922 period). But there are some neat ways I can think of to ask the question.
Finally—so what? What’s the context for shifts in language we haven’t noticed before, and how important is the difference between generational change and intrasubjective change? I think it says a lot, but I haven’t quite articulated what sort of explanatory theoretical framework I think these descriptive changes are evidence for. That’s worth doing.
Comments:
Regarding the question of different drivers of lin…
Jamie - May 4, 2011
Regarding the question of different drivers of linguistic change (#4 and 5): in the case of early medieval Francia, Carolingian linguistic reforms were evident earliest in texts produced with close connections to the court. We used to assume that the language reform had immediate and total effect on the textual record, so this observation has been an important qualification; but it still reflects the kind of intrasubjective change you mentioned that is easy for historians to identify because it maps onto the familiar analytics of power and other kinds of social relationships.
But as Roger Wright pointed out a few decades ago, the Carolingian language reforms were also engineered by non-native speakers from England. That observation recast what had once been seen as a restoration of the correct classical style into the more negative conclusion that the reforms were artificial and precipitated the split between Latin and what would eventually become French.
All this is to say that a generational view of linguistic transformation has political as well as social implications. A new way of viewing change that’s gradual and possibly unoffensive could soften the moral charge that so frequently accompanies discussion of changes in language. Or the discovery that linguistic change was, in fact, propelled by one overzealous age bracket could give more texture to the more traditional ways of explaining the capacity to influence.
Someone else posted a comment here that got lost, …
Ted Underwood - May 5, 2011
Someone else posted a comment here that got lost, I think, when Blogger went down for a few days.
I think determining that usage changes about half through generational succession, and half through a kind of collective drift, is a really fundamental and important result. You might consider some way of drawing this to the attention of people in historical linguistics.
When I took historical linguistics back in grad school, we focused heavily on phonology. In the case of phonology, the consensus is that change happens almost entirely through generational succession, and specifically through errors made by new language-learners. I suspect historical linguists have made similar efforts to think about semantic change, but I doubt they’ve studied usage from this statistical angle.
I also just want to underline your point that we don’t really have good ways of thinking about slow, long-term changes. Although I appreciate your kind reference to my blog, I would say that is on the whole as much of a problem in literary studies as it is in History. Literary scholars get deeply invested in periodization, which plays the institutional role for us that “area” plays for historians (it organizes hiring, publication, etc.) And that emphasis on period actually makes it pretty hard to talk about long, slow changes – the disciplinary payoff isn’t immediately clear.
I’m reposting a comment of Jamie’s that go…
Ben - May 5, 2011
I’m reposting a comment of Jamie’s that got lost in the blogger outage last week:
~~~~~~~~~~~
Regarding the question of different drivers of linguistic change (#4 and 5): in the case of early medieval Francia, Carolingian linguistic reforms were evident earliest in texts produced with close connections to the court. We used to assume that the language reform had immediate and total effect on the textual record, so this observation has been an important qualification; but it still reflects the kind of intrasubjective change you mentioned that is easy for historians to identify because it maps onto the familiar analytics of power and other kinds of social relationships.
But as Roger Wright pointed out a few decades ago, the Carolingian language reforms were also engineered by non-native speakers from England. That observation recast what had once been seen as a restoration of the correct classical style into the more negative conclusion that the reforms were artificial and precipitated the split between Latin and what would eventually become French.
All this is to say that a generational view of linguistic transformation has political as well as social implications. A new way of viewing change that’s gradual and possibly unoffensive could soften the moral charge that so frequently accompanies discussion of changes in language. Or the discovery that linguistic change was, in fact, propelled by one overzealous age bracket could give more texture to the more traditional ways of explaining the capacity to influence.