Machine Learning at sea
Note: this post is part 4 of my series on whaling logs and digital history. For the full overview, click here.
As part of my essay visualizing 19th-century American shipping records, I need to give a more technical appendix on machine learning: it discusses how I classified whaling vessels as an example of how supervised and unsupervised machine learning algorithms, including the ubiquitous topic modeling, can help work with historical datasets.
For context: here’s my map that shows shifting whaling grounds by extracting whale voyages from the Maury datasets. Particularly near the end, you might see one or two trips that don’t look like whaling voyages; they probably aren’t. As with a lot of historical data, the metadata is patchy, and it’s worth trying to build out from what we have to what’s actually true. To supplement I made a few leaps of faith to pull whaling trips out of the database: here’s how.
The climatological data is extraordinarily detailed about things like ocean temperature, but extraordinarily vague about even the most basic historical details. The complicated history of shipping logs (that’s a whole extra appendix I’ll have to write) means that almost all the information about any given voyage has been lost: in some records, even the ships themselves are not described, and we’re left only a set of points and temperatures completely disconnected from the individuals who wrote it down. Fortunately, the Maury collection is slightly better than that, but very little historical details from the voyages survive: we don’t know, for example, the cargo a ship was carrying, how big it was, or if it ran with steam or sail. Still, it’s still possible to get quite a good read on which of the voyages in Maury’s collection are whaling ones.
Basically, the ICOADS version of Maury’s data contains only three pieces of information about a ship, as opposed to an individual logbook reading. The point of the data was to find out about the world, not the ships themselves: so that data was generally not saved. The three pieces are the ship’s origin port, its destination, and its name. (There’s also the captain’s name, but I wasn’t able to get much useful information out of those on a first pass.)
The ship’s name is useful mainly for breaking all the distinct routes in the ICOADS database into voyages; this was probably the hardest part of the whole exercise. After a great deal of trial and error (running an algorithm and looking at maps to see if individual routes looked plausible) I came up with a set of rules where two points are judged to be on the same journey if a) they’re less than 30 days apart; b) they’re less than 1000 km apart; c) they have the same name; and d) no ship with that name was in two different places at the same time that calendar year. (The early ones were obvious, but produced total junk until I added the fourth).
Making the core unit ‘ voyages ’ instead of ‘ logbook-days ’ is first, but still doesn’t let me track whaling voyages. But the Maury data does have a number of whaling trips hard coded in. Many voyages simply say ‘ WHALING ’ in the destination field. Additionally, several other origin or destination ports host almost exclusively whaling voyages. Plotting New Bedford voyages on a map, for example, it’s quite clear that they’re going to whaling destinations. Those repeated squiggles off of Peru, Australia, Kamchatka, and Alaska are highly characteristic; and there’s not a single ship stopping in the major trade ports of Europe and very few in Asia. (All these maps are done with ggplot2 in R).

But that’s not enough, because many ships have empty destinations or don’t leave from New Bedford: a ship that sails from New Bedford to Chile, for example, before hitting the South Sea whaling grounds, might have an origin of ‘ Valparaiso ’ and a destination of “Pacific Ocean”; nothing in that will obviously scream ‘ whaling voyage ’, although you can look at a map and see that it is. This is where machine learning comes in handy, because it’s not so hard to classify whaling voyages from their courses alone.
First I created a training set to help identify whaling voyages. One half of it I presumed were whaling voyages based on the places mentioned in the logs: those were those that begin or end in a place including the names of New Bedford, Nantucket, New London, Cold Spring, or Sag Harbor, or mentions ‘ whaling ’ in the destination. Why those cities? Well, I actually started with just “whaling,” “New Bedford,” and “Nantucket,” but a few successive runs of the classifier—as well as checking up the history of the harbors—made it clear the other ports were almost all whaling voyages as well.
The second half of the training set is simply voyages that don’t mention those places: I just randomly sample the full set so we have as many non-whaling voyages as whaling voyages. Now we have a list of about 2000 trips, with a tentative estimate of whether they’re whalers or not:

I then divide the world’s oceans up into a grid with about 230 squares, and create a vector for each voyage of how much time it spends in each square: so a whaling ship might spend 5% of its trip east of Kamchatka, while a transatlantic clipper will be evenly spaced in all the squares between New York and Liverpool.
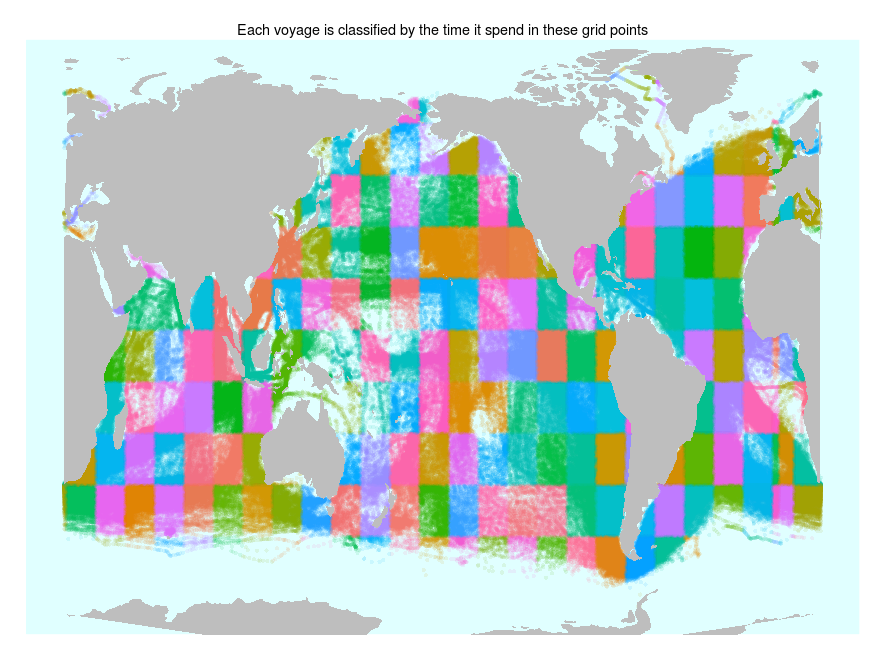
Click to enlarge
With this data, I can run a k-nearest-neighbor classifier that determines whether any given voyage more closely resembles a whaling voyage or a non-whaling one in the proportion of time it spends in each of those grid squares.
It’s a slightly funny training set, since it’s riddled with error: we have to bootstrap a bit with no gold-standard ground truth. Instead, I’m relying on my eyes: I can tell by visual inspection whether a voyage is whaling or not (if it wiggles on a whaling ground as seen in the other voyages, I’m pretty confident it is; if it doesn’t, it probably isn’t).
The hairy details: using the metadata tags, I made a training set equally-divided between whaling and non-whaling voyages: with k=3 and identical training and classification sets, each voyage gets reclassified as whaling or non-whaling. (I experimented with a cross-validatory k-means classifier where each voyage is classed according to the three ships closest to it except itself, but that, maybe surprisingly, produced worse results than allowing a voyage to vote on its own classification–in particular, almost all whaling voyages near Zanzibar ended up being written out of the set.) Given this sort of data, k is going to be arbitary; I like three because it preserves some very small clusters of whaling that are nontheless real, and will never reclassify a whaling voyage as non-whaling (or vice versa) unless _both_ of the nearby ships agree the metadata is unlikely. Since the metadata I’m using to find whaling voyages is not really true-false (it’s more like true-null), I run the classifier twice; first _only_ to define a few more whaling voyages to reclassify them, and then again after that to allow whaling voyages to switch to non-whaling based on similar voyages as well as vice-versa. Again, just looking for what works.
Tweaking the parameters to make it work requires some visual inspection: in this chart, for example, four maps show every possible combination of agreement and disagreement between the name method used to train the classifier and the classifier itself. Most voyages are in the two blue sections, where the classifiers agree: but more importantly, you can see in the red section on the lower left that the classifier does pick out a number of whaling voyages (near Kamchatka and the Galapagos, for example) that might otherwise be missed. The upper right shows the New Bedford, etc., voyages that don’t appear to be whaling based on the tracks: there is definitely a mistake or two, particularly near Japan, but most of these seem to be voyages from the whaling ports that trail off before actually hitting the whaling fields–it’s debatable whether these should be considered whaling at all.
I include all these charts not just because I like the colors, but because this sort of visual inspection was the only way to effectively test whether the clustering algorithm worked. I went through several iterations before settling on the one described here: and even this one obviously fails to catch a few whaling trips. I originally tried to use some more complicated measures, like the bendiness of the route, but that didn’t appear to add much to just looking at locations. If the goal is to visualize most of the whaling voyages and hardly any of the non-whaling voyages, this is good enough; if we wanted to do something more complicated (link it in to the New Bedford Whaling Museum’s crew manifests, say), we’d have to do some more.
In any case, once we move from the training set to the full one, the results are pretty intuitive. If you look at the results for one particular year, 1849, you can see the split between whaling and non-whaling voyages clearly enough: the Pacific is mostly but not entirely whaling (the gold rush is just starting to California, for instance); and the Indian and Atlantic oceans do get a few whaling classifications even though the vast majority of tracks are not.

(click to enlarge)
{kind=link}
I can also go back to those original port names in the logbooks and see which ones seem to participate in whaling voyages: this was mostly useful to find the ports to begin with, but it has some interesting points as well. (Ships sailing through ‘ Hawaii ’, for example, are much more likely to be whalers than those passing through “Honolulu.”; and while I don’t think Warren, Rhode Island was actually only a whaling port, it is in this set, maybe because whoever collected those logs was doing so from New Bedford.)

It’s a little problematic that only 90% or so of New London’s whaling voyages are flagged here: but remember, the classifier looks at where they went and my algorithms chop the voyages up if there are no log entries. Without perfect data, we can’t get perfect results.
Machine Learning with unstructured data
One last point: although k-nearest neighbor classification is good when we already know what sorts of voyages we want to track out, its close cousin k-means clustering lets us find the patterns inherent in the data without using any metadata at all. For getting a sense of the kinds of voyages that Maury collected, it can be invaluable.
K-means lets you choose any number: here I’ve asked it to divide up the Maury collection into 9 types of voyages, and to label each one with the percentage of voyages that follow that track. (I’ve just assigned the names by eye-balling them). Some of these are very familiar tracks, like the eastern seaboard route or the paths to Europe. A few others, like the cluster off the East Coast of Australia, are oddballs probably produced by gaps in the the data or my processing of it. But others are simply interesting: you can see that one of the classes, centered on Honolulu, comes close to whaling (although it includes the Pacific China trade as well).

Clusters of Voyages in the Maury collection.
Click to enlarge
More importantly, it gives a good sense of the general proportion of voyages. It’s very hard to look at a map and see what percentage are to and from Europe, and what percentage to Asia, because the frequently traveled routes are just so common compared to the rarely traversed ones. For data of uncertain provenance like this, though, the relative percentages are something we want to know: for example, I suspect that no representative sample would have, as Maury’s collection does, more ships sail around the Cape of Good Hope than from the East Coast to Europe.
This sort of clustering is most useful when you have no idea what sort of evidence you’re looking at. In those cases, it’s useful to be able to break a set down into some sort of ideal types to compare them against each other.
Luckily, though, humanistic data usually does come with some metadata, like the port descriptions I’ve been using, because the sort of people who digitize hundreds of items from the past rarely just throw it on the Internet without any information at all.
And there are big advantages to working from authoritative (which doesn’t mean perfect) metadata rather than interpretable (which doesn’t mean meaningful) clustering. Metadata-oriented models like knn-classification ‘ know ’ inherently that whaling can mean several sorts of unrelated things; but they really work because they’re anchored in human experience at two points:
The descriptions of voyages in the log books;
The analyst’s ability to change the parameters when things look wrong.
For the first of these, we need good librarians and archivists; for the second, we need good researchers/data analysts. There should be real benefits to this sort of work, but it’s also going to be as provisional and frankly error-prone as the model I describe above. I think that’s OK, but it does restrict the field where we’ll see this stuff work. We tend to equate computers with perfection, so there’s not always room in either the sciences or the humanities for work that can’t quite rectify the imperfections of humans or machines.
Comments:
This has been a fantastic series of posts. It woul…
Ryan Shaw - Nov 4, 2012
This has been a fantastic series of posts. It would make a great basis for a workshop. I may try to use it in my Organization of Information class next year to illustrate the use of metadata for purposes other than simply finding resources that meet a description.
By the way, in the last paragraph I assume you meant to write “We tend to equate computers with perfection”?
Thanks Ryan. Yep, that was some human imperfection…
Ben - Nov 4, 2012
Thanks Ryan. Yep, that was some human imperfection in action right there–fixed now.
Unknown - Jun 6, 2013
This comment has been removed by a blog administrator.
You can write about the tips on the blog. You migh…
Driving School - Nov 3, 2013
You can write about the tips on the blog. You might relinquish it’s fascinating. Your blog recommendations may thicken your commissions.