How Many Words are there in the English language?
Here’s what googling that question will tell you: about 400,000 words in the big dictionaries (OED, Webster’s); but including technical vocabulary, a million, give or take a few hundred thousand. But for my poor computer, that’s too many, for reasons too technical to go into here. Suffice it to say that I’m asking this question for mundane reasons, but the answer is kind of interesting anyway. No real historical questions in this post, though–I’ll put the only big thought I have about it in another post later tonight.
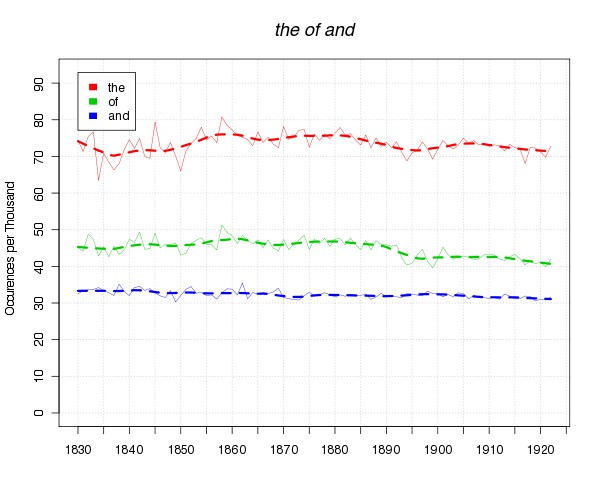
The number of unique words in the book database I’ve built is, literally, too many for event the computer to easily count. I’d guess it’s in the tens of millions. But most of those, I know, are typos from the OCR, which, I should probably emphasize, is quite bad. The 307th most common word, more common than “several” or “get,” is “tlie,” a misreading of “the.” Based on the rate of occurence of “the”, that would imply about 1 in 80 characters is misread, so almost 1 in 10 words. That’s not exact–not all characters are easy to read–but it gives a rough sense. There’s also some historical pattern to the incidence of the most common typos, which probably has to do with changes in fonts and print size caused by a) fashion and b) my having different publishers in the database. Here are the two most common typos, (in my new larger graph format!):

That raises concerns about data integrity, but I don’t think the OCR errors problems are common enough that we really have to worry about it. The most common words soldier on undaunted (I think that dip in ‘ of ’ is a real change in language, reflecting ‘ s ’s increasing use instead of that of of.)
I’m stuck counting typos as common as ‘ tlie ’ and ‘ tbe. I could spellcheck them out, but that would exclude a lot of proper names that I _do_ want counted. So how can I exclude the long tail of typos on less common words–things like “Cliester A. Artbur”, while still getting anything we ’d really like to see? I can only hold about 200,000 words in memory during the most complicated part of the perl script, so let’s hope that’s enough. Otherwise you’re going to have a read a bunch of posts complaining about install MySQL. If there are 400,000 words in the dictionary, that might not be.
I think, though, I’m not interested in the really rare words. In making these charts, I’ve been amazed at how frequent some of the words I want are in a sample this big. My favorite word, ‘ attention ’, is #567–it occurs 432,000 times in the corpus. (I’m working with about 2.75 billion words right now–Zipf’s law, which you can look up on wikipedia, seems to apply fairly well, as well as it does for wikipedia articles. So the most common hundred words account for about half of all the words. As with wikipedia, words start to get rarer, faster, somewhere around the 10,000th most common word–for the record, that’s “bail.”) Other words I’m interested in are relatively common too. “evolution” is #2447; ‘ efficiency ’, #5220. “Antietam,” “Shiloh,” and “Verdun” were some of the rarer battle sites, but all are in the top 30,000 words. “Telegraph” is number 46,000; a comparatively rare attention-related word like ‘ rapt ’ is 17,000.
Remember, I haven’t mentioned any stemming of words yet (I have it, but it’s easier not to use for easy stuff like I’ve done so far). A verb that gets used with attention takes up four ranks–pay (572), paid (636), paying (3550), and pays (6057). Those are all _well_ under the 180,000 word cutoff I’m using right now–I even get the alternate “payed” at spot 75,000, although “payest” doesn’t make the cut. But even with all the forms, and with all the proper nouns, it’s hard to think of a word rarer than number 50,000.
Now, a word ranked 50,000 is pretty rare–in my database, it happens to be “gummatous,” an adjective related to syphilitic sores. (That’s one I really don’t recommend looking it up on wikipedia unless you love medical photographs.) It shows up 1294 times, about once every 22 books. (Clearly we’ve got a fair amount of medicine in the sample–although remember, it shows up a several times some books.)
What are all those other words in the OED that I’m not counting? Honestly, I don’t know. It doesn’t seem worth it to try to scan in a huge wordlist and compare. As I did for book titles, I think random data exploration can help us get a sense what’s going on, though. Currently, I’ve dropped all words below about the 180,000th most common. So what do the words between 150,000 and 180,000 look like? Here’s a random sample, with the number of times they appear:
> sample(total[[3]][150000:180000],15)
Word
bridecake deduci biop maupin nadar chubs bitb bndge rnb
189 174 199 216 185 164 184 189 184
lepel oqce eompletely dramatised ducitur symptonis
169 166 200 204 171 202
(By the way, whenever I say “Here’s a random sample,” that’s actually what I’m giving you–I include the code so you’ll believe it).
What do we get? I might be wrong on one or two, but I count:
7 obvious typos, that show some of the ways the OCR fails–oqce for ‘ once ’, symptonis for ‘ symptoms, ’ etc.
3 rare last names (Maupin, Nadar, Lepel)
Two latin words (Ducitor and Deduci) There are actually a few American books published in foreign languages that I should remove–it’s easy enough to do. Latin is the most common language for these.
One inflection of an alternate spelling of a fairly common word (dramatised). That it’s this rare reassures me that I don’t have too many British books sneaking in, although I’m sure there are a few. Any ideas what the most canonical British vs. American spellings I should check to confirm this are?
One plural of a fairly rare word (Chubs). Note that the plural of the fish chub (rank 63,000) is simply chub, so this isn’t as common a word as it might seem.
One rare word (bridecake). Apparently a synonym for ‘ wedding cake. ’ I’ve never heard it.
Comments:
should we use the supercomputer (https://www.terag…
Hank - Nov 6, 2010
should we use the supercomputer (https://www.teragrid.org/) while we’ve got the chance? i have the password.
too many words. just need a simple answer
Anonymous - Jun 2, 2013
too many words. just need a simple answer
English Language has the maximum number of words t…
Unknown - Dec 3, 2014
English Language has the maximum number of words than any other language. Every day many words are added in the dictionary. These at one platform words can be found where learning is fun filled with different fun filled strategies i.e. www.vocabmonk.com