More thoughts on topic models and tokens
I’ve been thinking a little more about how to work with the topic modeling extension I recently built for bookworm. (I’m curious if any of those running installations want to try it on their own corpus.) With the movie corpus, it is most interesting split across genre; but there are definite temporal dimensions as well. As I’ve said before, I have issues with the widespread practice of just plotting trends over time; and indeed, for the movie model I ran, nothing particularly interesting pops out. (I invite you, of course, to tell me how it is interesting.)
So here I’m going to give two different ways of thinking about the relationship between topic labels and the actual assigned topics that underlie them.
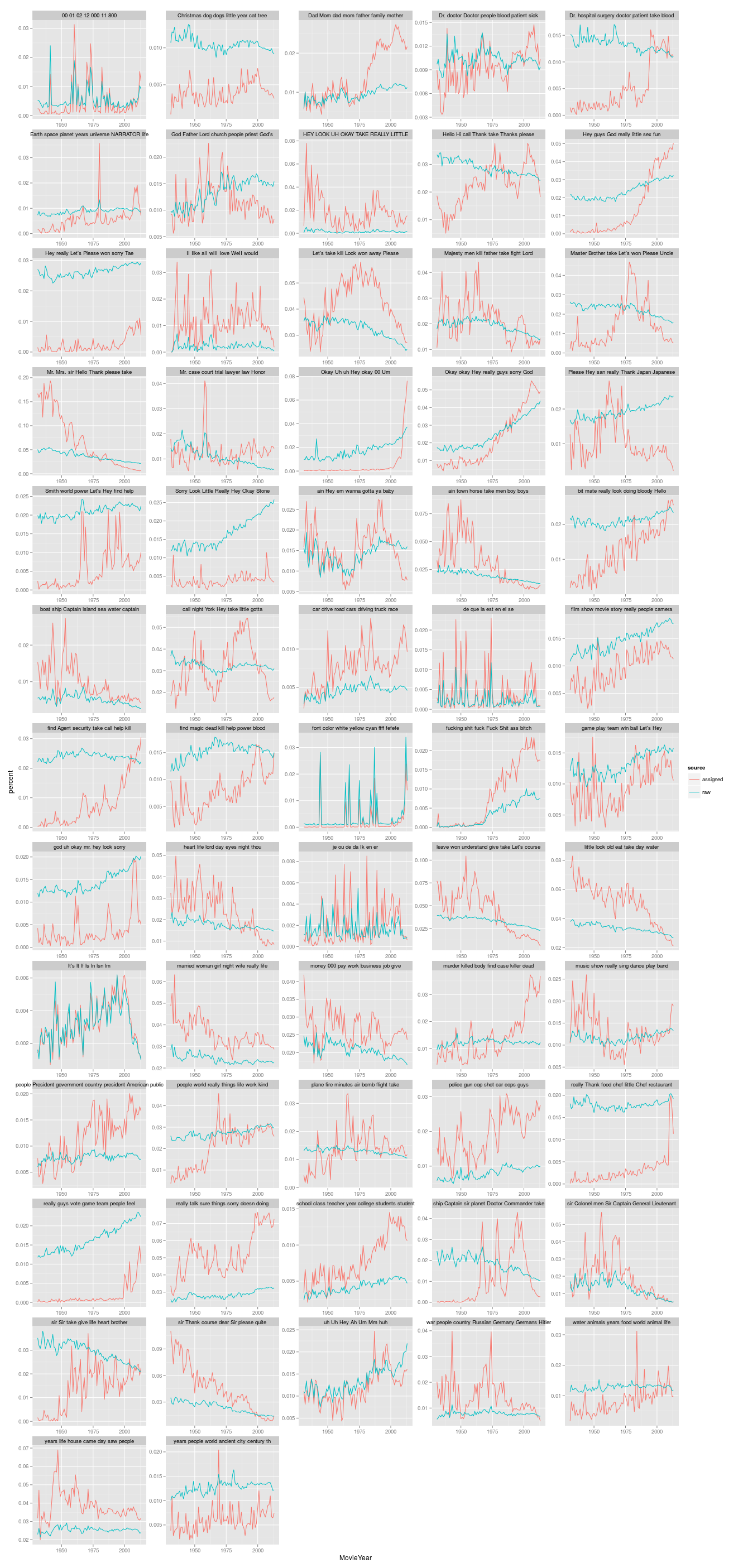
One way of thinking about the tension between a topic and the semantic field of the words that make it up is to simply just plot the “topic” percentages vs the overall percentages of the actual words. So in this chart, you get all the topics I made on 80,000 movie and TV scripts: in red are the topic percentages, and in blue are the percentages for the top five words in the topic. Sometimes the individual tokens are greater than the topic, as in “Christmas dog dogs little year cat time,” probably mostly because “time” is an incredibly common word that swamps the whole thing; sometimes the topic is larger than the individual words, as in the swearing topic, but there are all sorts of ways of swearing beside the topic assignments.
In some cases, the two lines map very well–this is true for swearing, and true for the OCR error class (“lf,” “lt” spelled with an ell rather than an aye at the front).
In other cases, the topic shows sharper resolution: “ain town horse take men”, the “Western” topic, falls off faster than its component parts.
In other cases the identification error is present: towards the top, “Dad Mom dad mom” takes off after 1970 after holding steady with the component words until then. I’m not sure what’s going on there–perhaps some broader category of sitcom language is folded in?
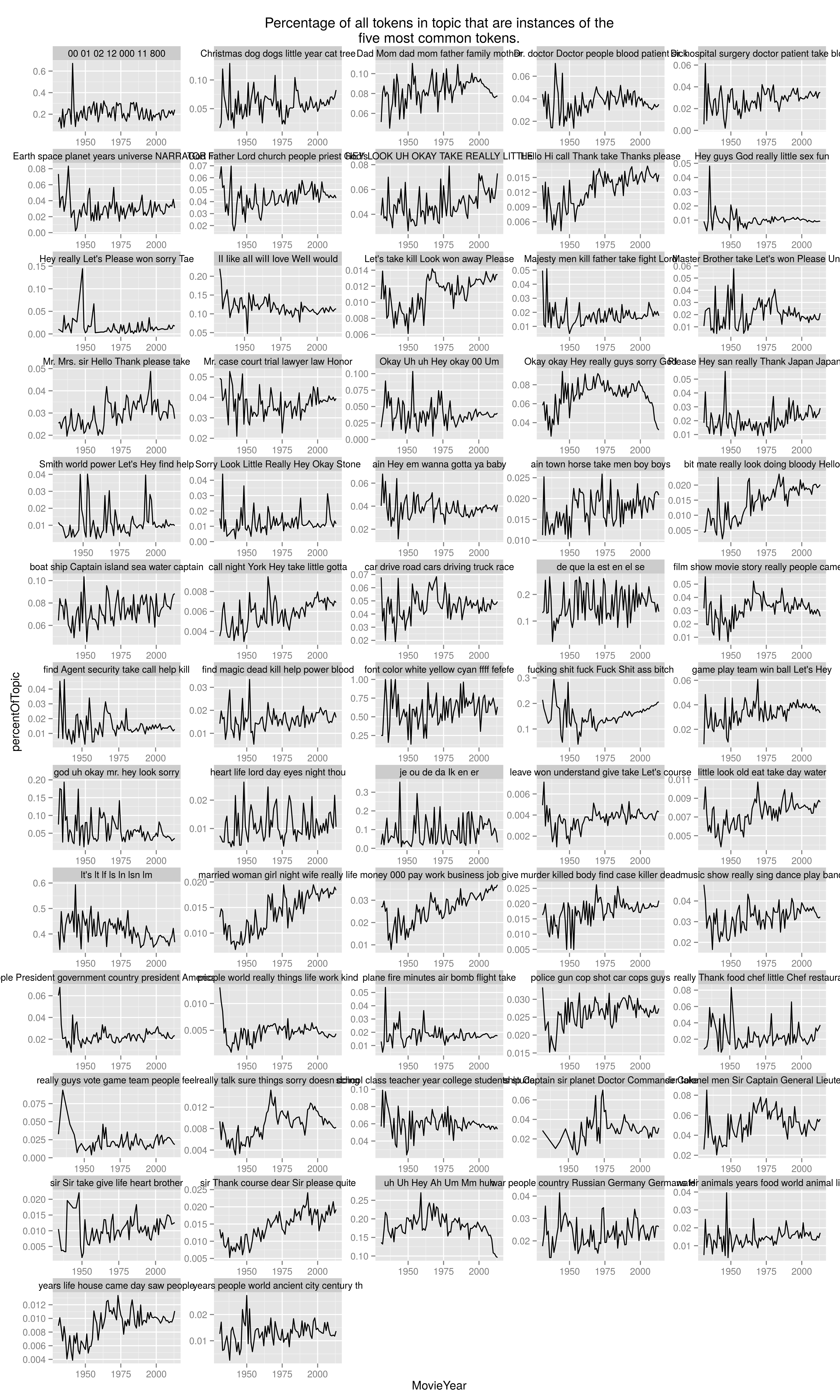
Another approach is to ask how important those five words are to the topic, and how it changes over time. So rather than take all uses of the tokens in “Christmas dog dogs little year cat time,” I can take only those uses assigned into that full topic: and then look to see how those tokens stack up against the full topic. This line would ideally be flat, indicating that the label characterizes it equally well across all time periods. For the Christmas topic, it substantially is, although there’s perhaps an uptick towards the end.
But in other topics, that’s not the case. “Okay okay Hey really guys sorry” was steadily about 8% composed of its labels: but after 2000, that declined steadily to about 4%. Something else is being expressed in that later period.”Life money pay work…” is also shifting significantly, towards being composed of its labels.
On the other hand, this may not be only a bug: the swear topic is slowly becoming more heavily composed of its most common words, which probably reflects the actual practice (and the full of ancillary “damn” and “hells” in sweary documents. You can see the rest here.
These aren’t particularly bad results, I’d say, but do suggest a further need for more ways to integrate topic counts in with results. I’ve given two in the past: looking at how an individual word is used across topics:
and slope charts of top topic-words across major metadata splits in the data:
Both of these could be built into Bookworm pretty easily as part of a set of core diagnostic suites to use against topic models.
The slopegraphs are, I think, more compelling; they are also more easily portable across other metadata groupings besides just time. (How does that “Christmas” topic vary when expressed in different genres of film?) Those are questions for later.